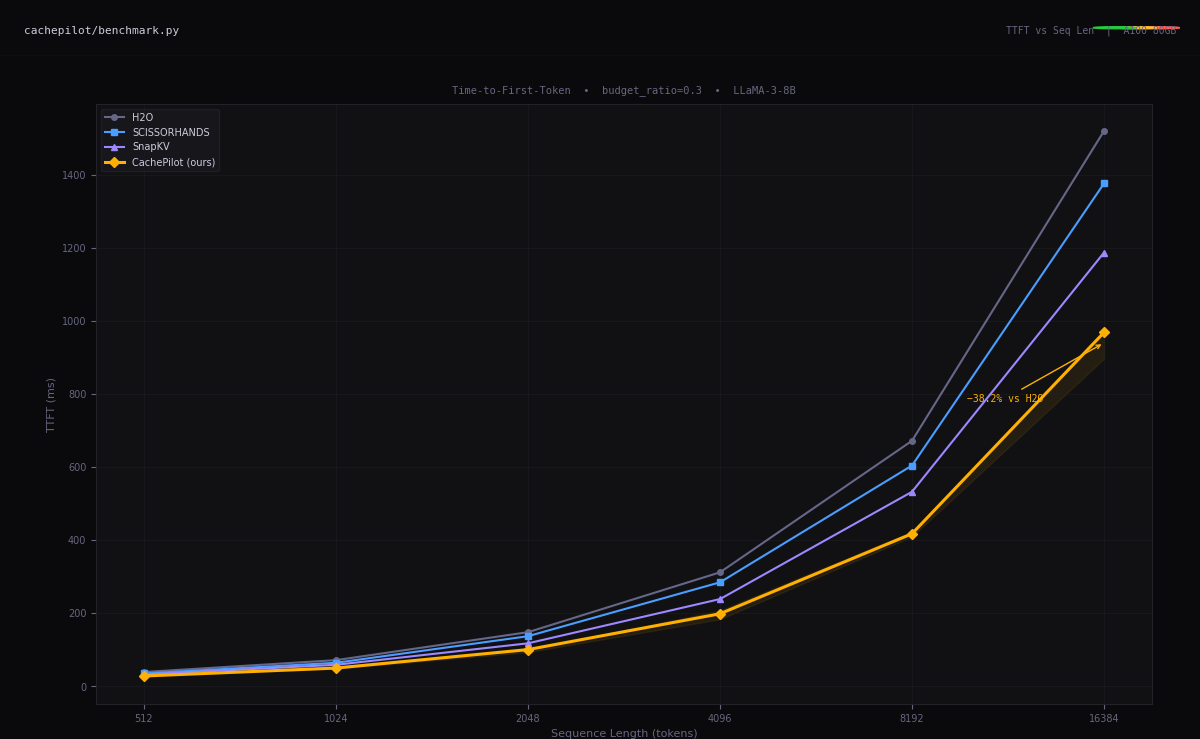
01AI Inference Optimization
KV cache constraints, attention approximation, speculative decoding. The gap between research throughput and production latency is the problem.
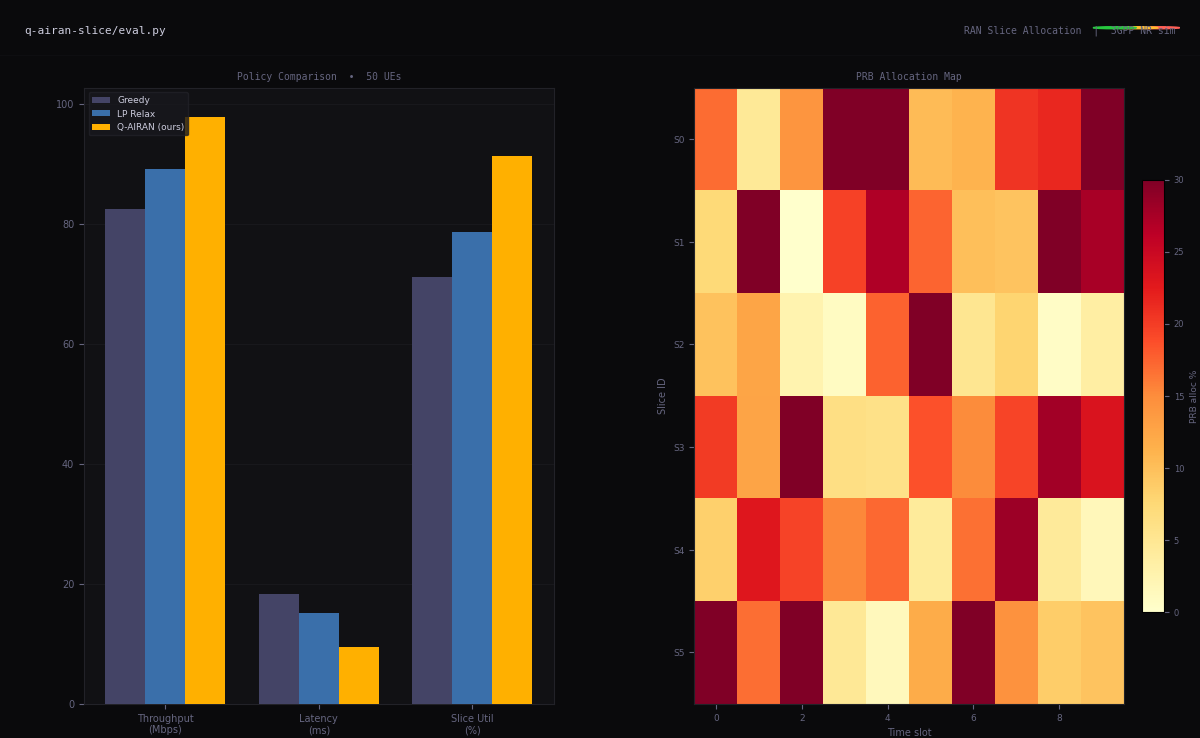
026G and AI-Native Networks
Intelligent RAN slicing, URLLC, O-RAN disaggregation. Networks that adapt to inference workloads — not the other way.
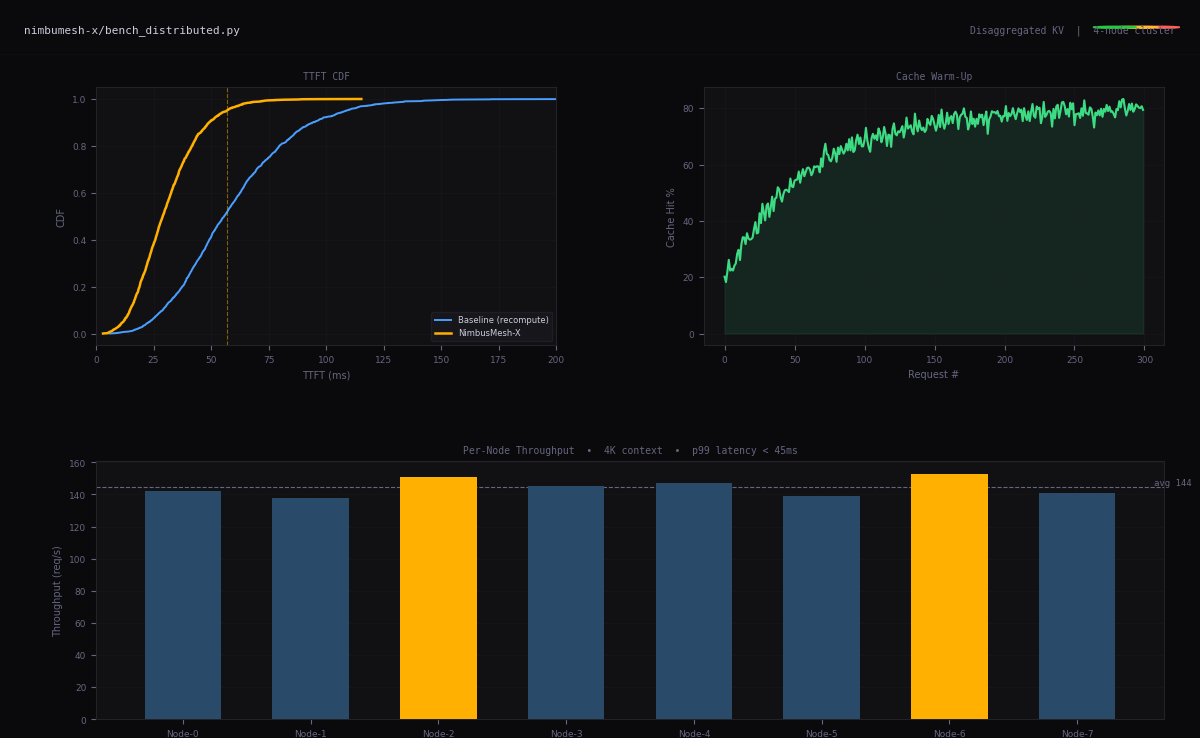
03Distributed Systems
Disaggregated architectures, fault-tolerant pipelines, latency under contention. Systems that degrade gracefully, not catastrophically.
04Compute Optimization
Memory bandwidth vs compute tradeoffs, CUDA kernel design, operator fusion. Every cycle is a constraint worth reasoning about.
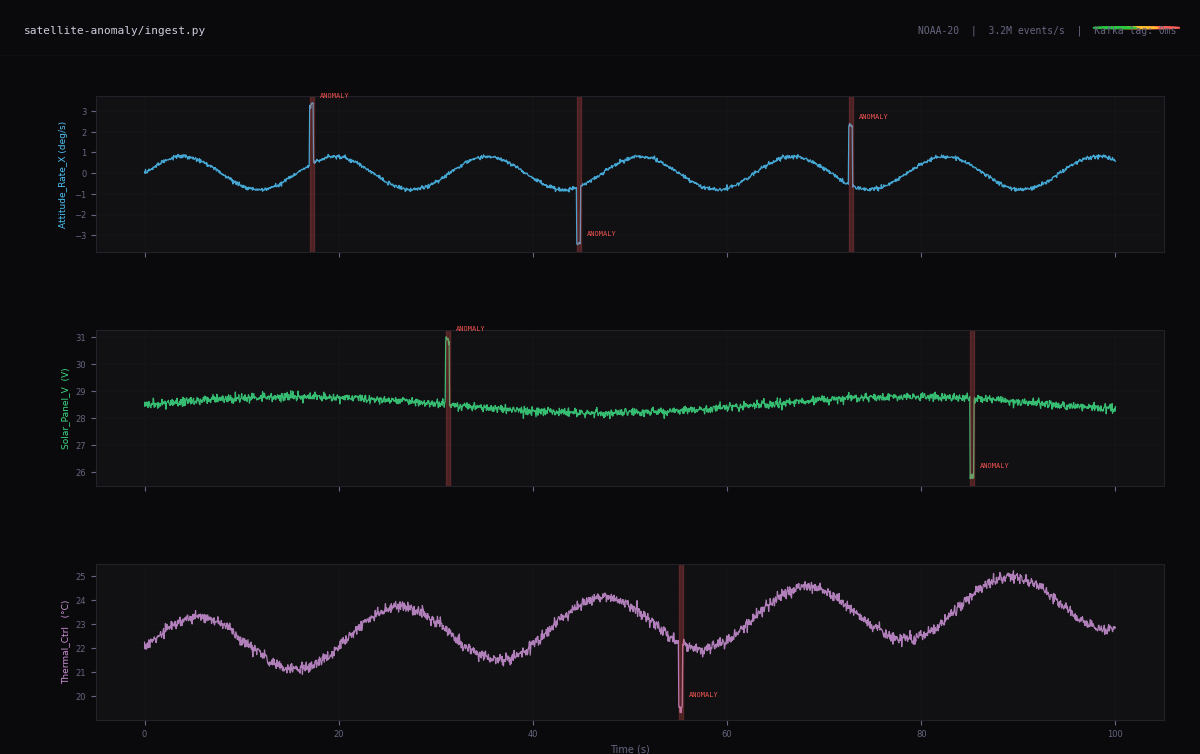
05Robotics and Edge AI
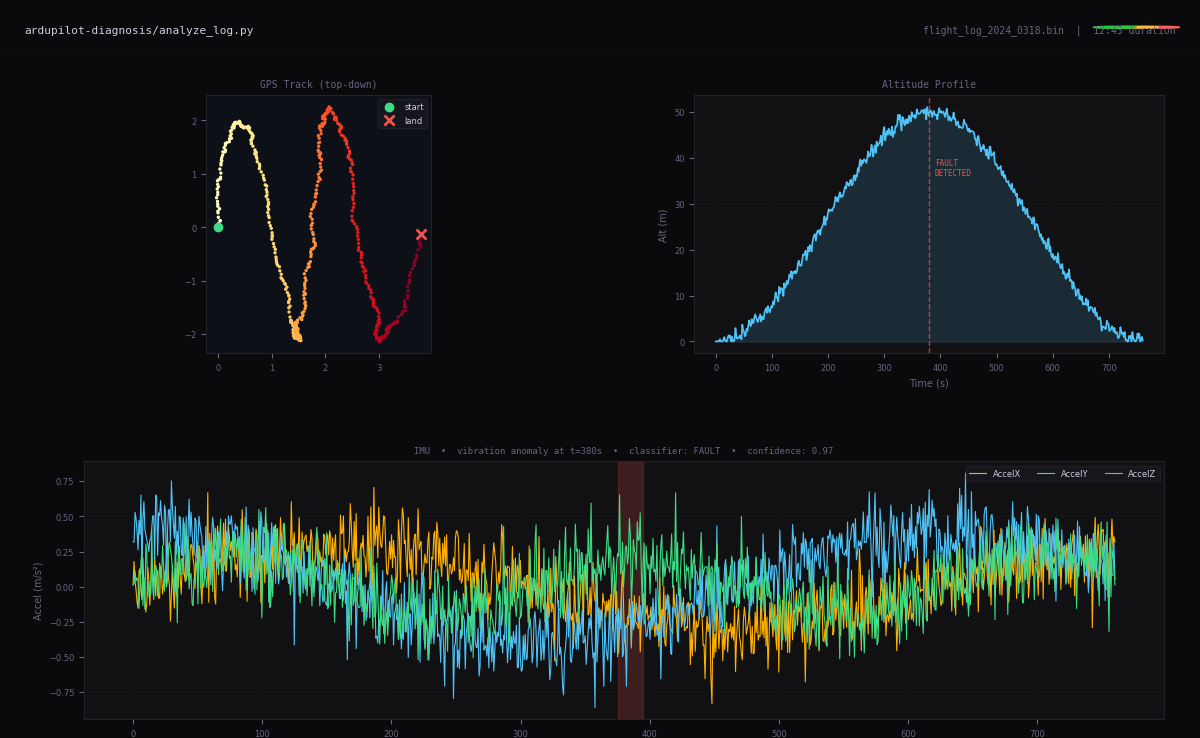
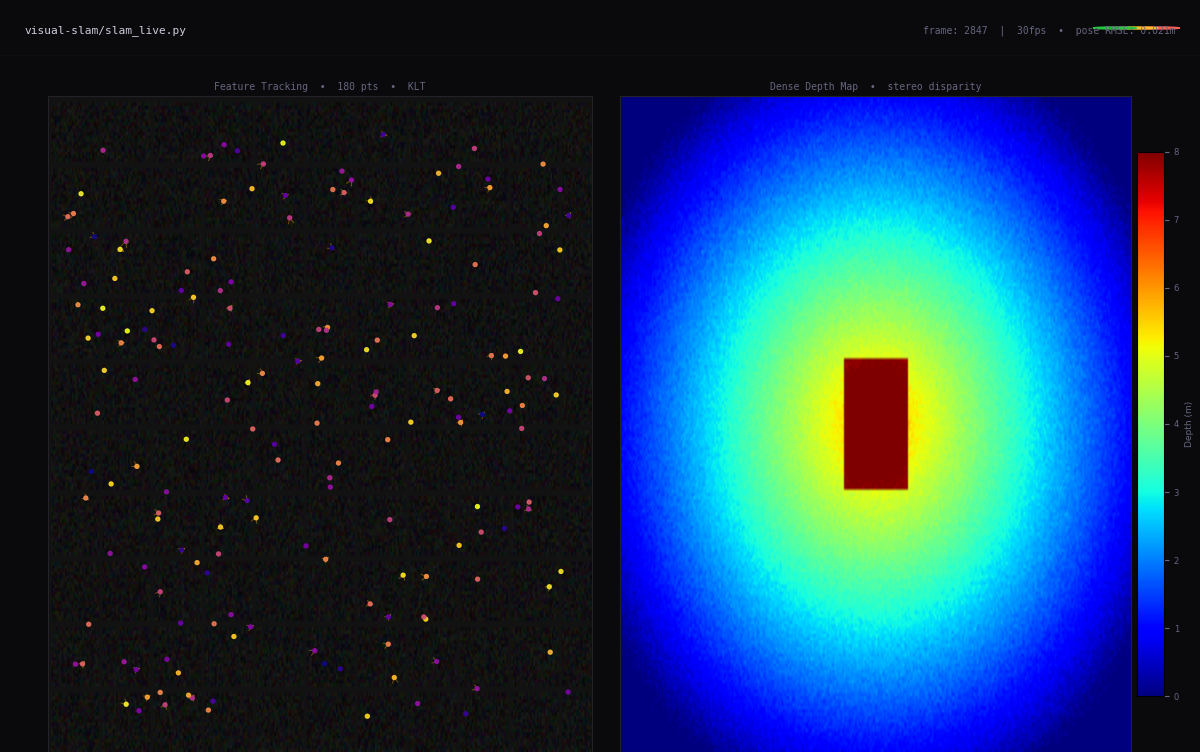
Real-time perception, sensor fusion, ROS2 pipelines. AI that works when the network doesn't exist and latency is physical.
06Quantum Computing
QUBO, QAOA, quantum-inspired optimization. Already in Q-AIRAN-SLICE — next step is real circuit implementation.